Executive Summary
The basic goal of this research project is to obtain a scalable model to map building information onto a common unified schema. This is done using pre-trained models on set of selected source buildings with the help of domain adaptation. Construction engineers and Architects could use an interface built on this schema to track and monitor different technical elements in a building's architecture like temperature sensors, HVAC systems and their locations in the building. This project attempts to use multiple domain adaptation techniques and compares their performance against each other to realize the feasibility of such a solution.
Research Project Overview
Scrabble framework provides a versatile approach to map building information in the form of thousands of data points on to a common schema, successfully retrieving semantic metadata from unstructured raw metadata. This is done while reusing known information in existing buildings to reduce the amount of effort for domain experts to provide input labels. Modern building infrastructure is supported using sensors and networked into a Building Management System(BMS). BMSes manages data from sensors such as room temperature, power meter; from actuators such as dampers for control of air flow, fans for exhaust; and from configurations such as the temperature setpoint for heating. Brick is a metadata schema which provides for a complete vocabularies and relationships to describe such resources in a machine readable format, thus enabling portability of applications. Scrabble is currently implemented and evaluated for five buildings using Brick as the target schema.
The high-level objective through this research project is to obtain a more comprehensive interoperability in internet of things by providing for a robust scalable implementation of Scrabble framework. In the absence of labeled data for a certain classification task, domain adaptation is usually an attractive method given that labeled data of similar nature but from a different domain are available. The intention is to scale the framework to multiple buildings, each of which would correspond to a domain shift or dataset bias, by reducing the adaptation reduce the difference between the training and test domain distributions and thus improving generalization performance of the framework. Given the labeled source building data and the target building input data points, the purpose is to obtain the predictions for the target building labels using Domain Adaptation.
Introduction to Domain Adaptation
During the last few years, new methodologies like Domain Adaptation have improved computer vision applications drastically. Domain Adaptation is a sub-discipline of machine learning where a model is trained on a source distribution and is used in a different (but related) context on a target distribution. For example, from the image below, the bags from domain 1 do not have any background but the bags from domain 2 have a slightly complex backgound. This is called domain shift. If an image classifier is trained on domain 1 and used to predict on domain 2, the model would experience a performance degradation on some level.
 Domain Shift
Domain Shift
Domain Adaptation basically attempts to eliminate the difference between the distribution of labeled source domain on which a classifier is trained and that of unlabel target distribution to which the classifier is applied. The level of relatedness between the source and target domains hereby usually determines how successful the adaptation will be.
Domain Adaptation in Scrabble
Scrabble uses an active learning framework for normalising the metadata of sensors in multiple buildings by using a transferrable intermediate layer. Scrabble makes use of machine learning algorithm called Conditional Random Field (CRF) Classifier to map a sentence from target building to a set of Brick tags. This is trained with the help of source samples or examples from domain experts. These Brick tags form a reusable Intermediate Representation (IR) for effectiveness in mapping it to the final labels.. A multi-Layer Perceptron(MLP) is used to map the Tags to the corresponding Tagsets. Scrabble iterates through all the target building data points until it identifies all building labels with high confidence.
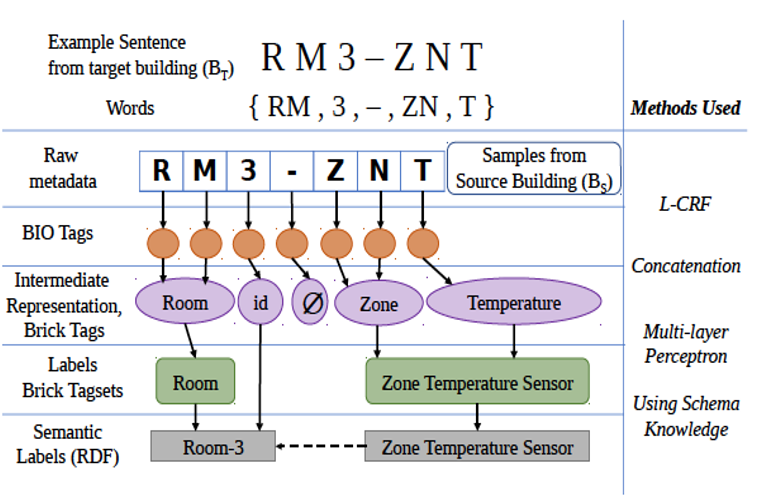 Scrabble Architecture
Scrabble Architecture
Given this underlying hierarchical structure of Scrabble, domain adaptation can be implemented in two specific layers. The CRF layer when the tokens from a sentence are converted to Tags or in the MLP layer to convert the Intermediate Representation (IR) tags to the final tagsets. In this research, we attempt on implementing domain adaptation in the latter by obtaining training or source building information and using transfer learning techniques to map the tags from target building to the tagsets despite the shift in the domain.
Implementation
1. Neural Adapter
This method aims at transferring knowledge in an incremental progressive way within the same domain rather than to the other domains. It is assumed that the target output domain is included in the source output domain. A neural adapter is used to mitigate the differences between the source and target label distributions and learn from them. This provides additional important information to the final model. In the Scrabble context, we would use the source building tags to tagset conversion information and transfer the knowledge to a target building where new label categories appear. Following is a detailed explanation on the progressive transfer learning approach.
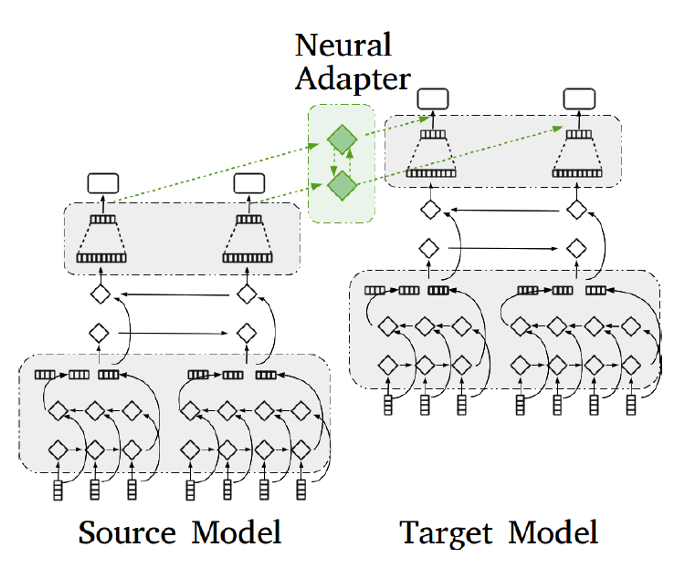 Implementation Architecture
Implementation Architecture
Source: https://www.aaai.org/Papers/AAAI/2019/AAAI-ChenLingzhen.6418.pdf
i. Training of a source model
A labeling model Ms is trained on a source dataset Ds to obtain optimal parameters These are saved and reused for transfer learning. We use a multi-layer perceptron to train this model.
ii. Parameter Transfer
The parameters in the output layer is initialized with the weights drawn from the normal distribution of the saved weights from the pre-trained source model Ms, taking the mean and standard deviation of the values. The weights not in the output layer are set with the same values as obtained from the optimum weights from Ms. We test this condition by implementing various other combinations of weight assignment for parameter transfer as explained in the future sections.
iii. Target model training
Here, we use the transferred parameters and train the target training data by designing an MLP and using this MLP along with the fixed source model to obtain multi-label classification predictions on the input. Here, we introduce an extra layer of MLP between the source and the target MLP outputs, called the neural adapter. This component solves the disagreement in annotations between the source and target data. This layer helps to map the predictions from the output space of the source domain to that of the target domain. We obtain the element-wise summation of the output from fully connected source layer and the extra layer to that of the fully connected target output layer, following with the output consists in a softmax to obtain the final result.
2. Adversarial Domain Adaptation
Adversarial adaptation methods have become increasingly popular approach to minimise a domain discrepancy with respect to a domain discriminator. This is closely related to the generative adversarial learning or GANs where two networks generator and discriminator are pit against each other and both try to outperform the other, hence reaching a state of domain generalisation that can result in better target scope predictions. This works under the assumption that probability distribution of source domain is not equal to the probability distribution of the target domain but the conditional probability distribution of the labels given an instance from both the domains are the same.
The overview of this method is to perform some kind of transformation on bot source and target domain to get the distributions closer. The classifier is trained on the transformed source domain and since both the distributions are now on the same scale, the model obtains better results on target domain. Assume the neural network used for transformation is denoted by ‘T’ with the parameters ‘P’. The instances from source and target domain are denoted as ’s’ and ’t’. The transformed vector is denoted as Vs and Vt for source and target.
Then,
T(s,P) = Vs and T(t,P) = Vt
The objective is to obtain the probability distributions of Vs and Vt closer to each other.
P(Vs) = P(Vt)
This method comprises of the following components.
This MLP performs transformation on the source and target distribution
ii. Label Classifier
This MLP network performs classification on the source domain data points and predicts the labels.
iii. Domain Classifier
This MLP predicts whether the output of the feature extractor is from the source or target distribution. The idea is that it classifies the domain of the transformed input.
The intuition is that the feature extractor produces a type of transformation that domain classifier is not able to classify the domain of the transformed instances. This is done by training the feature extractor and domain extractor in a way that feature extractor is trained to maximize the domain classification loss, while the domain classifier is trained to minimize the domain classification loss. The label predictor is trained to predict the labels on the transformed instances since the source is labeled. The feature extractor thus learns to produce discriminative and domain-invariant features.
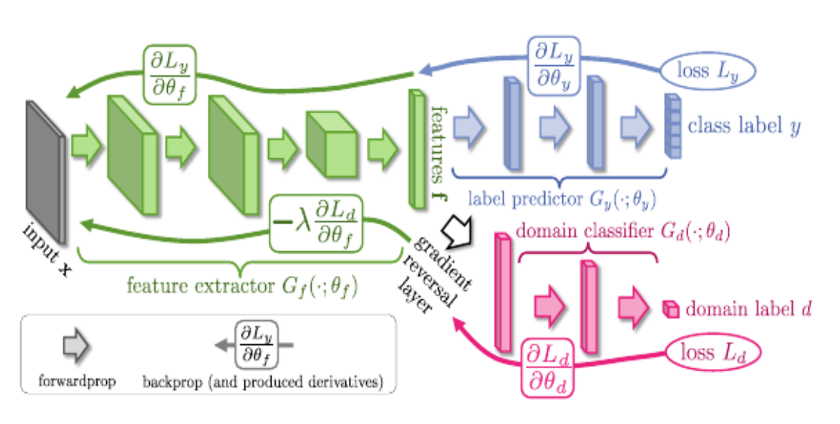 Adversarial Domain Adaptation architecture
Adversarial Domain Adaptation architecture
Source: https://arxiv.org/pdf/1409.7495.pdf
We place a gradient reversal layer between the feature extractor and the domain classifier which acts as an identity function during forward propagation but during back propagation it multiplies the input by -1. Intuitively, this layer is leading to the opposite of gradient descent, that is, it is performing gradient ascent on the feature extractor with respect to the classification loss on the domain predictor.
Results
These two methods - Neural Adapter and Adversarial Domain Adaptation are used in the Scrabble context to perform domain adaptation. Once we obtain the tags from the sentences from the target building data points, we perform domain adaptation in the second stage of the framework where the Intermediate Representation (IR) Tags are converted to the Tagset labels. We use samples from both source and target building to form the training data, to incorporate both the domains for the training process. The datapoints are vectorised to a csr matrix using CountVectorizer, including the response variable which is the tagset label. The domain index of the training data is also obtained and fed into the modelling process. Multiple variations and combinations are tried and tested to achieve better results.
Evaluation of the performance of a model was done using set accuracy since that this was a multi-label classification with a lot of sparse values in the output. A multi-layer perceptron with two hidden layers to classify labels was considered as a baseline model for comparison. This model was trained without any sort of domain adaptation. The set accuracy obtained by these models were compared with the baseline model implemented without any adaptation technique. The results obtained were as shown in the below plot.
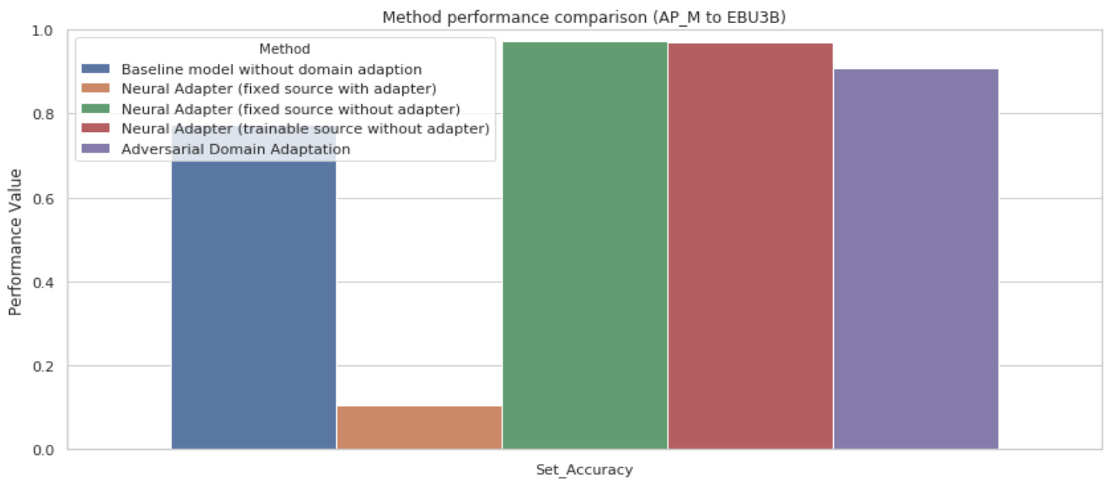 Set Accuracy for all Methods using ‘EBU3B’ as Source building and ‘AP_M’ as Target Building
Set Accuracy for all Methods using ‘EBU3B’ as Source building and ‘AP_M’ as Target Building
The neural adapter model with a direct source and target output linkage layer performed the best. The adversarial domain adaptation performed well in discriminating the domain with 0.5 accuracy and the labels with greater than 0.8 accuracy. One of the reasons the adversarial domain adaptation did not work the best is probably that the gradient reversal layers leads to vanishing gradient problem once the domain predictor has achieved maximum accuracy. Another reason might be that same weights are being used for performing the transformation on the source domain and the target domain. Since, both source and target domain might have different features therefore, shared weights might lead to less number of parameters for learning independent features and transforming both the distributions.
Business Applications of Domain Adaptation
These techniques could be useful in digital advertisements, where partners/sellers contact potentially interested online users with their products. Within the digital advertisement domain, there are multiple platforms like user re-targeting or prospecting. Prospecting basically means targeting un-tapped user-base. One of the challenge with prospecting is partner-cold start problem, which is on-boarding a new partner to the prospecting platform. Domain adaptation could be used to solve this problem by leveraging the large amount of re-targeting data and transferring the model results to the prospecting domain.
Domain Adaption has a great potential in visual classification tasks. Using Convoluted Neural Networks(CNNs) with transfer learning techniques can result in robust multi-domain image classifications and result in better classification. One of the examples for such an implementation could be applied in e-commerce websites to classify product images to specific sections or sub-sections.
Deep fake, which is an infamously hot topic currently use Generative Adversarial Networks to create domain shifts/noise in a real image. Domain adaptation techniques can be used to classify a real image from a fake one and prevent massive misuse of this technology.
References
Click
PDF to view more details on this project.
 Thive Global
Thive Global